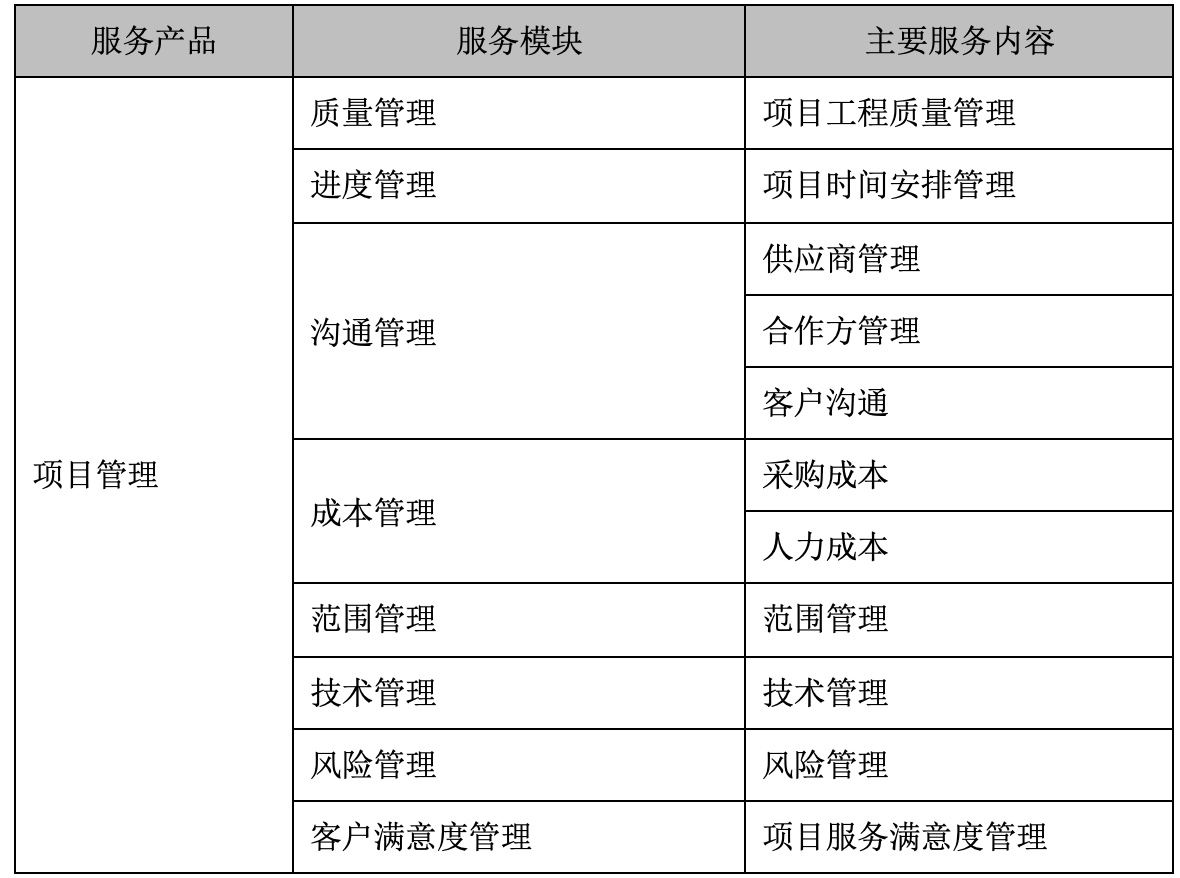
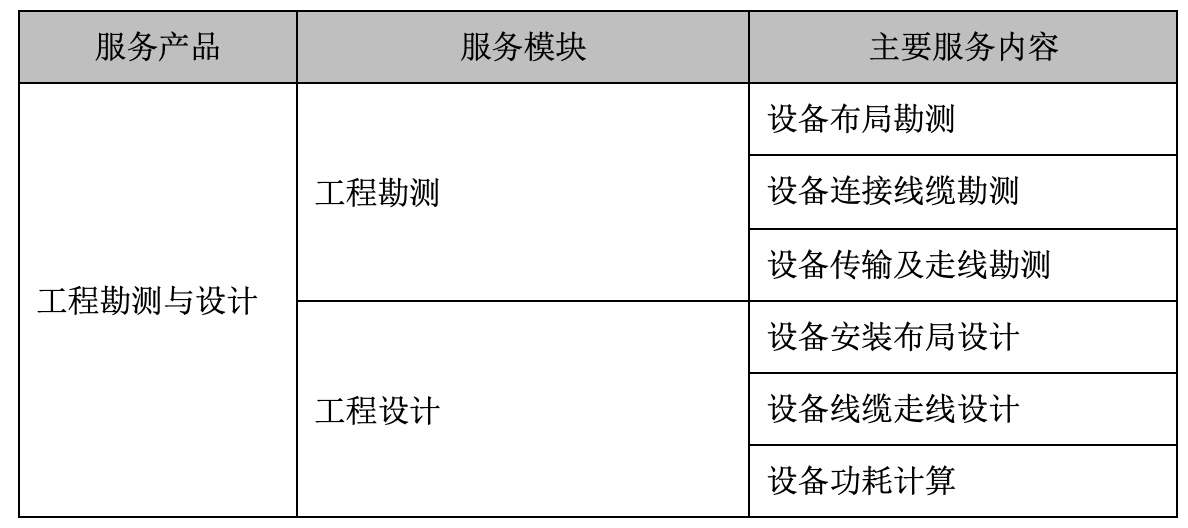
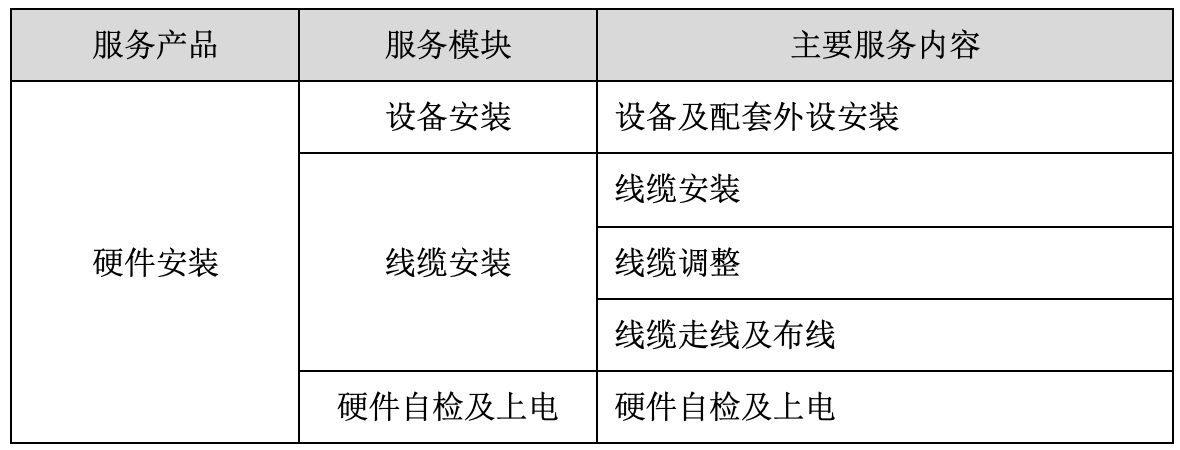
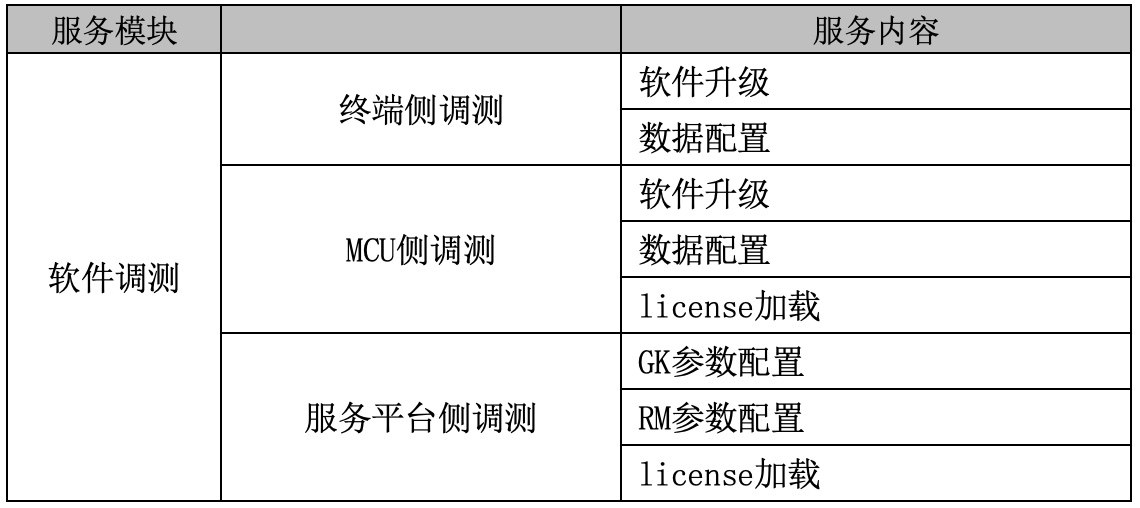
无论是解析视频文件或者通过网络传输,其实都是一串字节序列。H264 码流就是按照一定的规则组织排列的字节串。
一、码流的组织形式
在 H264 中完全没有 I 帧、P 帧、B 帧、IDR 帧的概念,之所以沿用这些说法是为了表明数据的编码模式。H264 码流的组织形式从大到小排序是:视频序列(video sequence)、图像(frame/field-picture)、片组(slice group)、片(slice)、宏块(macroblock)、子块(sub-block)、像素(pixel)。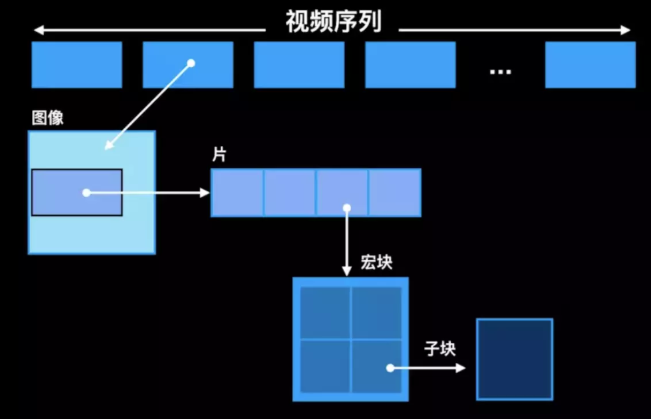
二、码流功能的角度
从码流功能的角度可以分为两层:视频编码层(VCL)和网络提取层(NAL)
- VCL:进行视频编解码,包括预测(帧内预测和帧间预测),DCT 变化和量化,熵编码和切分数据等功能,是为了实现更高的视频压缩比。
- NAL:负责以网络所要求的恰当的方式对 VCL 数据进行打包和传送。
VCL 是管理 H264 的视频数据层,是为了实现更高的视频压缩比,那 VCL 究竟是怎么管理 H264 视频数据的呢?抛开 H264 压缩算法细节来看就 3 步:
- 压缩:预测(帧内预测和帧间预测)-> DCT 变化和量化 -> 比特流编码;
- 切分数据,主要为了第三步。这里一点,网上看到的“切片(slice)”、“宏块(macroblock)”是在VCL 中的概念,一方面提高编码效率和降低误码率、另一方面提高网络传输的灵活性。
- 压缩切分后的 VCL 数据会包装成为 NAL 中的一部分。
下面要重点讲解下 NAL。
三、网络提取层(NAL)
NAL,英文全称为 Network Abstraction Layer,这块和 H264 压缩算法无关,涉设计出 NAL 的目的就是为了获得 “network-friendly”,即为了实现良好的网络亲和性,即可适用于各种传输网络。
终于要讲 NAL 了,但是,我们需要先看 NAL的组成单元 - NALU。
3.1 NAL单元 - NALU
NALU 的格式如下图(引用H264 PDF)所示:

很明显,NALU 由头和身体两个部分组成:
- 头:一般存储标志信息,譬如 NALU 的类型。前面讲过 NAL 会打包 VCL 数据,但是这并不意味着所有的 NALU 负载的都是 VCL,也有一些 NALU 仅仅存储了和编解码信息相关的数据;
- 身体:存储了真正的数据。但实际上,这块也会相对比较复杂,前面其实也提到过 H264 的一个目的是“网络友好性”,说白了就是能够很好地适配各种传输格式。所以根据实际采用数据传输流格式,也会对这部分数据格式再进行处理。
3.2 NALU Header
首先,NALU Header只占 1 个字节,即 8 位,其组成如下图所示:

forbidden_zero_bit
在网络传输中发生错误时,会被置为 1,告诉接收方丢掉该单元;否则为 0。
nal_ref_idc
用于表示当前NALU的重要性,值越大,越重要。
解码器在解码处理不过来的时候,可以丢掉重要性为 0 的 NALU。nal_unit_type
表示 NALU 数据的类型,有以下几种:
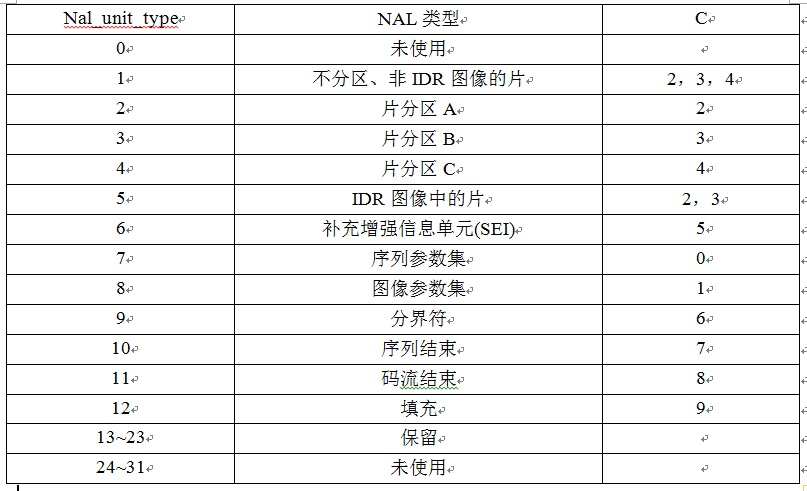
其中比较注意的应该是以下几个:
- 1-4:I/P/B帧,如果 nal_ref_idc 为 0,则表示 I 帧,不为 0 则为 P/B 帧。
- 5:IDR帧,I 帧的一种,告诉解码器,之前依赖的解码参数集合(接下来要出现的 SPS\PPS 等)可以被刷新了。
- 6:SEI,英文全称 Supplemental Enhancement Information,翻译为“补充增强信息”,提供了向视频码流中加入额外信息的方法。
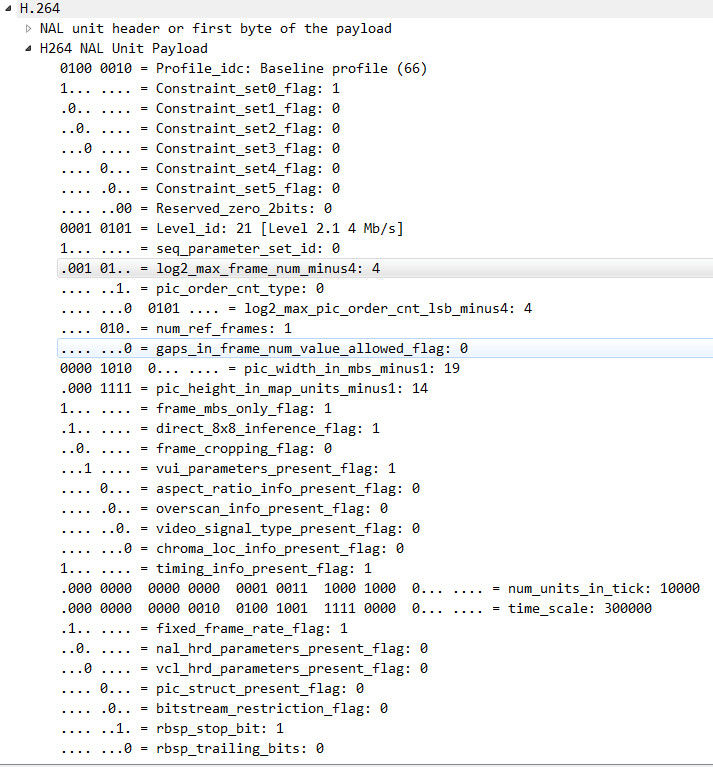
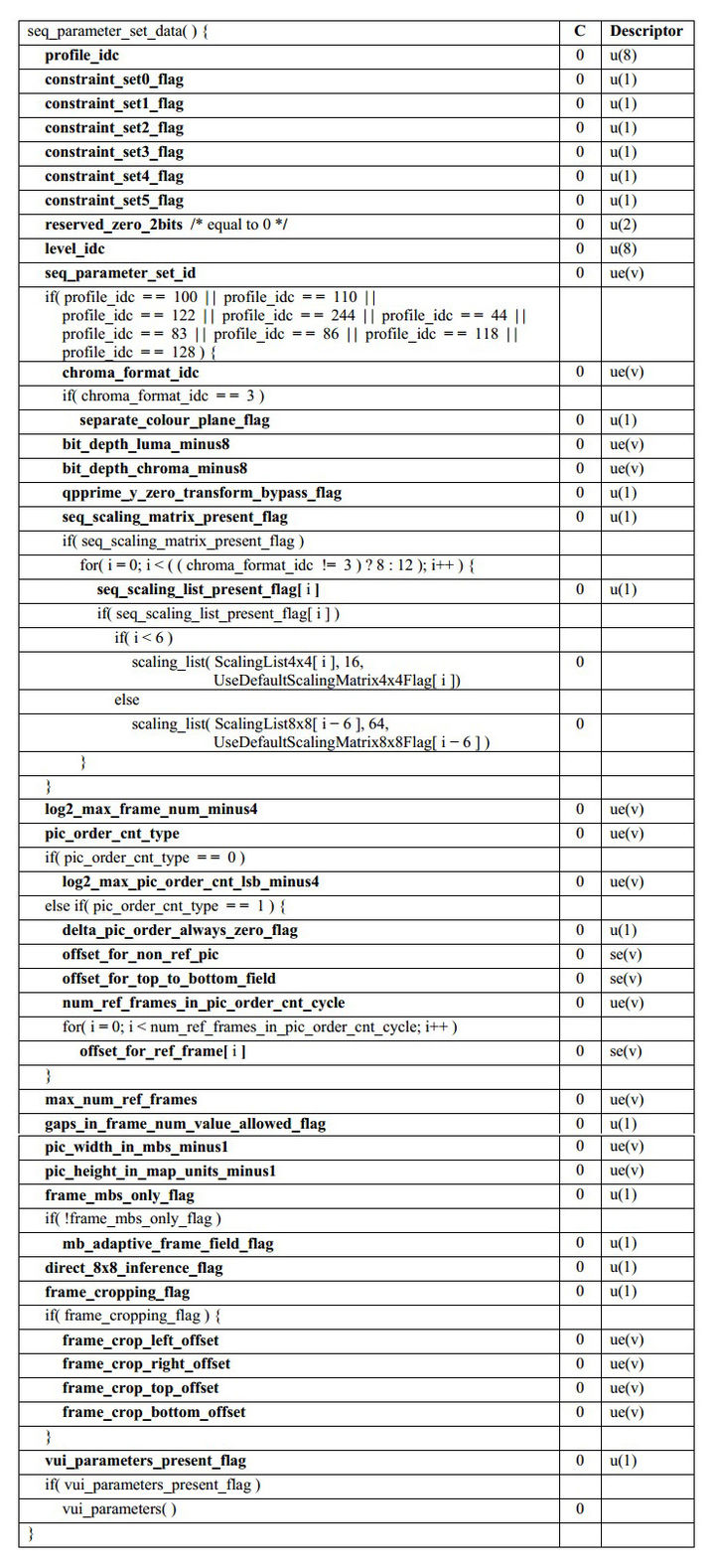
- 7:SPS,全称 Sequence Paramater Set,翻译为“序列参数集”。SPS 中保存了一组编码视频序列(Coded Video Sequence)的全局参数。因此该类型保存的是和编码序列相关的参数。
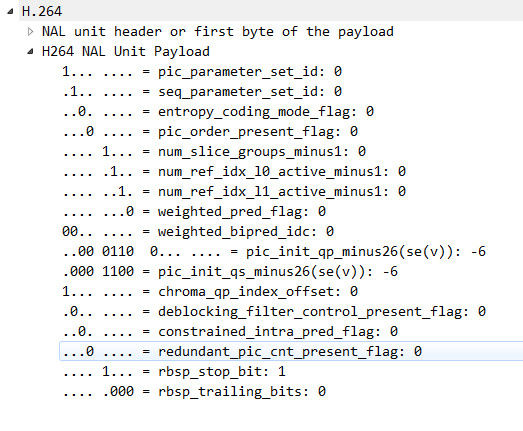
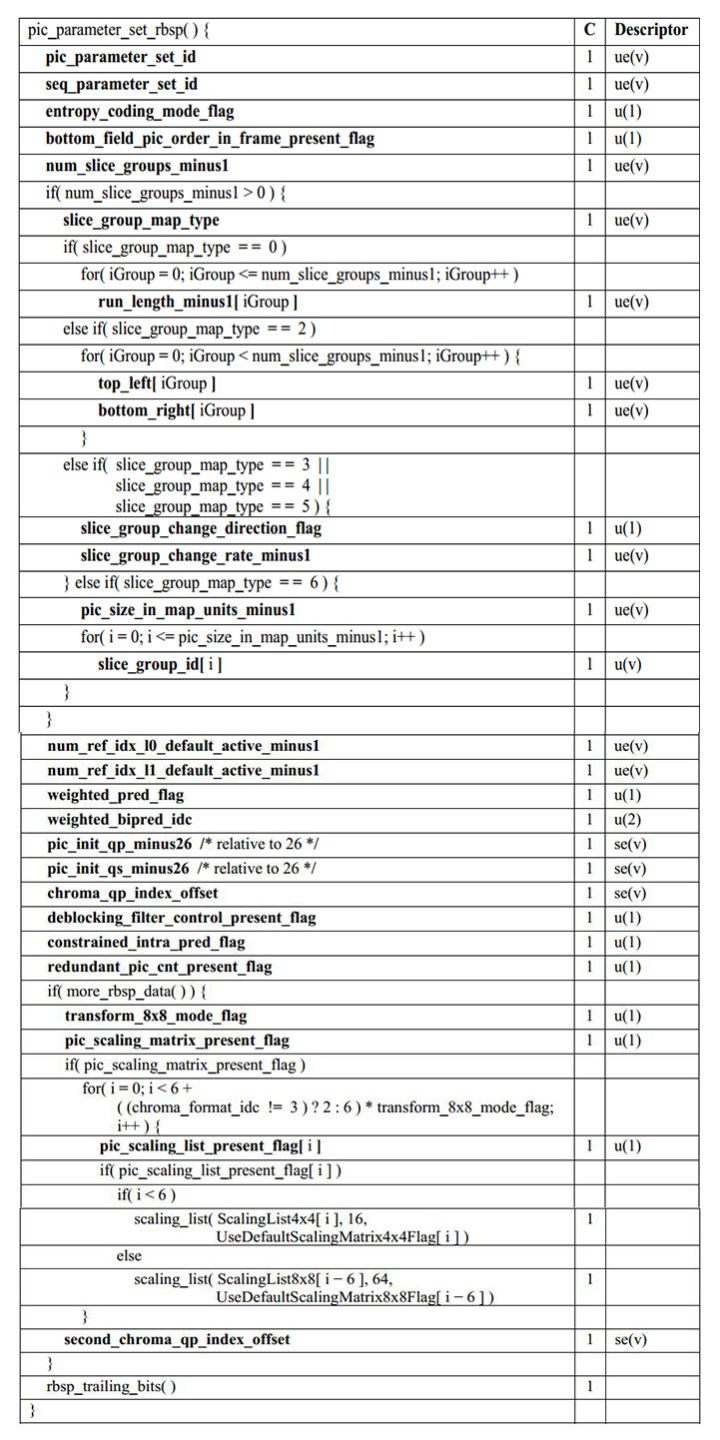
- 8: PPS,全称 Picture Paramater Set,翻译为“图像参数集”。该类型保存了整体图像相关的参数。
- 9:AU 分隔符,AU 全称 Access Unit,它是一个或者多个 NALU 的集合,代表了一个完整的帧,有时候用于解码中的帧边界识别。
特殊的 NALU 类型:SPS和PPS
SPS 和 PPS 存储了编解码需要一些图像参数,SPS,PPS 需要在 I 帧前出现,不然解码器没法解码。而 SPS,PPS 出现的频率也跟不同应用场景有关,对于一个本地 h264 流,可能只要在第一个 I 帧前面出现一次就可以,但对于直播流,每个 I 帧前面都应该插入 sps 或 pps,因为直播时客户端进入的时间是不确定的。
3.3 NALU Payload
很少有资料会称身体部分为 Payload,绝大部分资料对 NALU 组成的定义是这样子的:
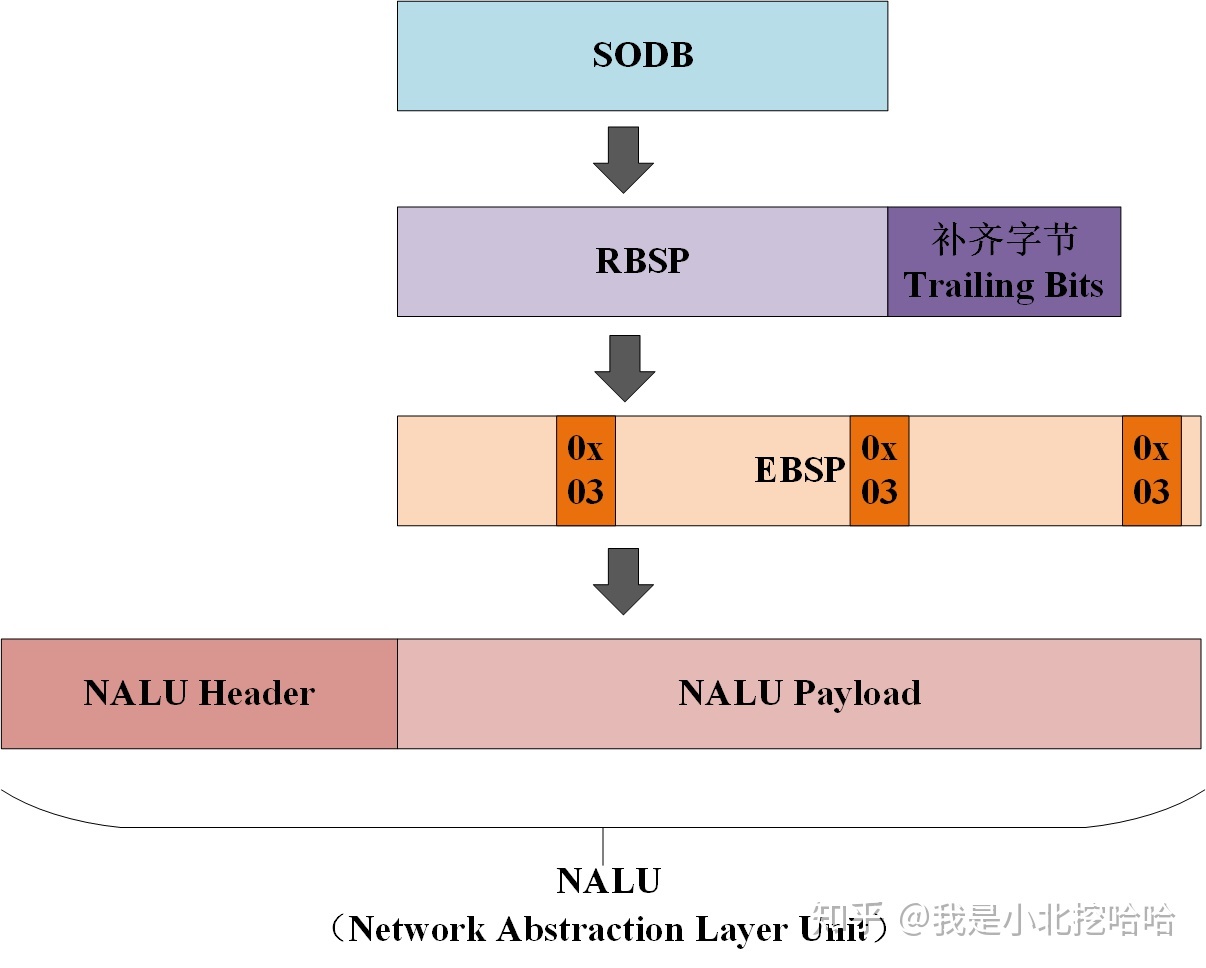
1 | NALU = NALU Header + SODB // 定义1 |
于是新的问题来了:SODB,RBSP和EBSP都是什么东西呢?这块概念,在博客NALU详解二(EBSP、RBSP与SODB)中介绍得非常清楚,总结来说就是:
SODB
英文全称 String Of Data Bits,称原始数据比特流,就是最原始的编码/压缩得到的数据。
RBSP
英文全称 Raw Byte Sequence Payload,又称原始字节序列载荷。和 SODB 关系如下:
1 | RBSP = SODB + RBSP Trailing Bits(RBSP尾部补齐字节) |
引入 RBSP Trailing Bits 做 8 位字节补齐。
EBSP
英文全称 Encapsulated Byte Sequence Payload,称为扩展字节序列载荷。和 RBSP 关系如下:
1 | EBSP :RBSP插入防竞争字节(`0x03`) |
这里说明下防止竞争字节(0x03):读者可以先认为 H264 会插入一个叫做 StartCode 的字节串来分割 NALU,于是问题来了,如果 RBSP 中也包括了 StartCode(0x000001 或 0x00000001)怎么办呢?所以,就有了防止竞争字节(0x03):
1 | 编码时,扫描 RBSP,如果遇到连续两个 0x00 字节,就在后面添加 防止竞争字节(0x03);解码时,同样扫描 EBSP,进行逆向操作即可。 |
最后,以一幅图总结 NALU 这段内容:
四、码流解析的角度
H264 码流实际可以理解为由一个一个的 NALU 单元组成。(下图中的 RBSP 类似 NALU Payload)

前面提到的一帧图像(I 帧, P 帧, B 帧)就是一个 NALU 单元,NALU 单元除了代表图像外还能包含其他类型的数据,如 PPS 和 SPS。
五、H264更详细的分层结构
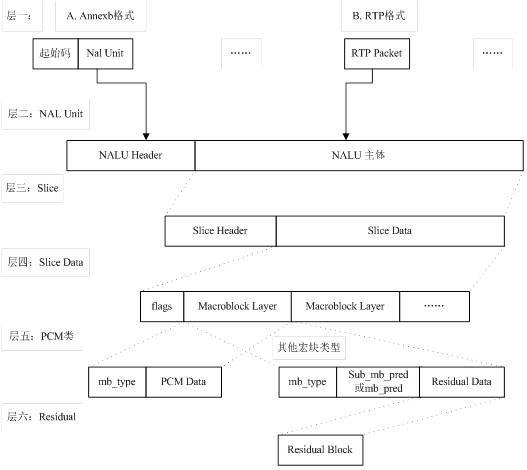
- 第一层:比特流。该层有两种格式:Annexb 格式和 RTP 格式。
- 第二层:NAL Unit 层。包含了 NAL Header 和 NAL Body 信息。
- 第三层:Slice 层。一帧视频图像可编码成一个或者多个片,每片包含整数个宏块,即每片至少 一个宏块,最多时包含整个图像的宏块。
- 第四层:Slice data 层。Slice 由宏块(macro block, MB)组成。宏块是编码处理的基本单元。
- 第五层:PCM 类。
- 第六层:残差层。
片的目的:
为了限制误码的扩散和传输,使编码片相互间保持独立。片共有 5 种类型: I 片(只包含 I 宏块)、P 片(P 和 I 宏块)、B 片(B 和 I 宏块)、SP 片(用于不同编码流之 间的切换)和 SI 片(特殊类型的编码宏块)。
六、扩展:怎么区分 NALU 的边界?
了解了 NALU 之后,关于 H264 格式,还有一个问题:解码器怎么知道一个 NALU 要结束了?或者说它怎么区分 NALU 的边界?
要回答这个问题,就必须了解 H264 的打包方式,通俗来说是H264 如何组织一连串的 NALU 为完整的 H264 码流。目前 H264 主流的两种格式:
- Annex-B:本文关于 NALU 的很多细节介绍都是 Annex-B,它依靠前文提到的 Start Code 来分隔 NALU,打包方式如下:
1 | [start code]--[NALU]--[start code]--[NALU]... |
- AVCC:笔者对这个格式了解的不多,从网上找到很多资料知道以下几点:
- 由 NALU 和 extradata/sequence header 组成,由于在 extradata/sequence header 中存储了 NALU 的长度,因此 NALU Payload 不需要做字节对齐,不过防竞争字节还是有的;
- SPS 和 PPS 被放在了 extradata/sequence header。
- 打包方式如下:
1 | [SIZE (4 bytes)]--[NAL]--[SIZE (4 bytes)]--[NAL]... // 请注意,SIZE一般为4字节,但是具体以实际为准 |
至于为什么要有这两类格式,还需要查阅更多的资料。不过 StackOverflow 上关于Possible Locations for Sequence/Picture Parameter Set(s) for H.264 Stream的回答可以帮助深入了解这两种格式,推荐阅读。
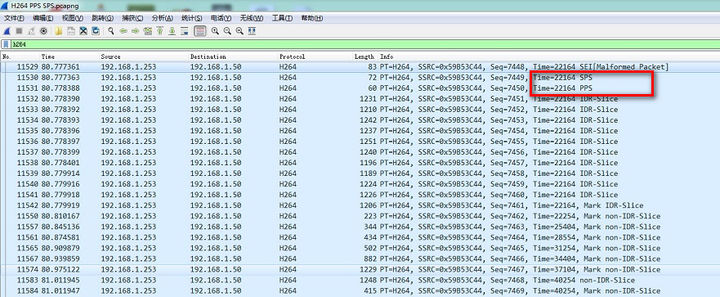
下面是一个 H264 码流,可以看到每个 NALU 前有一个 StartCode(0x000001 或 0x00000001),作为 NALU 的分割符:

分析其中比较有代表性的3帧:
- 00 00 00 01 67
00 00 00 01 是一个 NALU 开始,67 是Header, 二进制为 0110 0111, nal_unit_type 为00111,即7为 SPS 帧。 - 00 00 00 01 68
68 二进制为 0110 1000,nal_unit_type 为00111,即 8 为 SPS 帧。 - 00 00 00 01 65
65 二进制为 0110 0101,nal_unit_type 为 00101, 即 5 为 IDR 帧。
参考: